


Verifying Model Input and Output
ZK Summarizer
There are two parts to the ZK summarizer: the creation of the summarizer model, and verifying the summarizer’s computation.
1. Summarizer model training
The summarizer model is used to summarize the output of multiple Frenrug LLM agents into a single action that can be executed on-chain (namely, do nothing, buying, and selling.)
The Summarizer intent computation model was created using a small scikit-learn logistic regressor. We followed the below steps to train the model for summarizing whether different copies of the Frenrug agent
Dataset creation: Simulating Frenrug Agent turns
100s of human-initiated prompts of internal gameplay with the Frenrug Agent was each used to generate 3 copies of Frenrug Agent output, to simulate each Frenrug agent’s decision on the human prompt (for whether to buy, sell, or do nothing).
Dataset Creation: Assembling labels
For each Frenrug agent’s decision, the response corresponded to ordinal labels of (0,1,2) respectively for do nothing, buying, and selling.
The task for the summarizer was then sentiment classification of various responses.
2 labellers and more were assigned internally to each sentiment from individual Frenrug agents: assigning scores of 0,1,2, creating hundreds of individual examples.
Creating feature vectors
BERT embeddings of dimension 768 were used to create feature vectors from each individual Frenrug agent text response.
Robustness to Diverse Number of Frenrug Agent Votes
There may be scenarios where there are variable numbers of Frenrug Agent node participating in a vote of whether to do nothing, buy, and sell. The summarizer model dataset enumerated various possibilities in the training dataset to be robust to diverse number of agents, and also to augment the number of examples.
Once individual rows of Frenrug agent responses had labels, group labels were created for the summarizer model.
Heuristics for voting (for instance, simple majority for buying, selling, etc.) were used to algorithmically aggregate individual scores of each agent (for instance, if in a group of 3 agent buys, 2 were a buy, the end score would be a buy).
To use all of the data that was labelled, all combinations of each groups of 3 were used (irrespective of order).
Both feature vectors and labels were aggregated (through simple averaging for the former, and heuristics for the latter).
In addition to the original rows, now each grouped combination was used to augment the dataset.
Up-sampling: Imbalanced dataset
The original dataset was heavily imbalanced towards doing nothing: a lot of user turns were chatting with picky agents. To increase the chance of predicting a buy and sell, the data was upsampled to include equal proportion of buy, sell, and do nothing.
Training and Pick hyperparameters
A simple logistic regressor was trained on the training split of the above upsampled dataset with feature vectors of averaged BERT embeddings and labels of 0,1,2.
To prevent overfitting and to do feature selection of the 768 embedding features, L1 regularization was used with various $\alpha$ values that was hyperparameter searched.
After L1 regularization, only 69 features were non-zero. Sparse features that stay unused were pruned later.
Evaluation
After training the logistic regression model, it was evaluated with Precision, Recall, and F1 metrics of each of the 3 categories on the test dataset.
Prune model for on-chain storage
Given the sparsity of the feature set (only 69 features were non-zero) and the cost of storing embeddings on-chain (for the model verification step), the corresponding embedding indices corresponding to non-zero weights are stored. These 69 indices are then used to index the embeddings at inference time, to be used as input to the summarizer model at inference time.
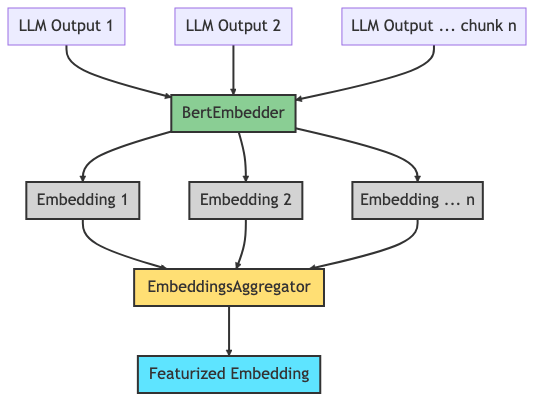 Pre-processed input for training and running inference for the summarizer model.
Pre-processed input for training and running inference for the summarizer model.
2. Verifiability
Frenrug leverages multiple nodes to process a given request to increase robustness and reduce censorship resistance.
However, given the inherent stochastic nature of large language models, the same query can result in different output values. For example, some results may be semantically similar yet phrased differently. How do we aggregate and decide the final outcome in an intelligent yet transparent way?
Enter the ZK Summarizer: a regression based learner that processes the averaged featurized embeddings of the LLM output and determines the corresponding action to take, all the while leveraging zero knowledge proofs and data attestation to prove both the validity of the result on chain as well as data provenance.
The overall flow of the ZK Summarizer is as follows:
Raw LLM Output
The Frenrug front end triggers multiple queries to the LLM Inference Service via the Infernet node. These results include both the raw response as well as the featurized embeddings that will be used to compute the overall intent.
Averaged Feature Embedding
After the responses to the queries arrive, the featurized embeddings are aggregated on chain for transparency and sent to the summarizer model for intent computation.
Summarizer Computes Action
The summarizer model processes the aggregated feature embedding and computes an intent output.
Proof Generation
Hash of Feature Embedding + Output stored on chain for attestation used for generating proofs. The input and output of the summarizer model is packaged and sent to the proving service for proof generation and attestation.
Zero Knowledge Proofs:
We leverage the EZKL Library to implement ZK Proofs for our summarizer intent model, using the following visibility setup:
- Hashed inputs. Inputs are hashed for data attestation purposes.
- Private model. Model weights are private, allowing us to update the model with new training data transparently.
- Public outputs. The output is public in the interest of transparency.
Together with the Infernet ML SDK, we convert our scikit learn based model into a torch model, and serve both inference and proving via the provided services.
Data Attestation
While zero knowledge proofs can ensure that a given model result is valid, there is no guarantee that the actual model input was not tampered or altered prior to being used to generate the proof. To that end, we store and attest to the hash of the model inputs on-chain using hashed visibility setting in the EZKL Library. (We attest to the hash of the input rather than the actual raw inputs for efficiency reasons: the validity of the hash can be individually verified as we publish the raw input on chain as well).