


Retrieval Augmented Generation
RAG for the Frenrug Agent
For the frenrug agent, we experimented with expanding the context window to multi-turn, as well as adding in crypto twitter data as well as using retrieval augmented generation for summarizing the context window.
To do this, we found some existing crypto sentiment tweets, created embeddings, and injected them into the context window.
We also experimented with condensing previous conversation histories (through storing conversations, and using cosine-similarity to fetch relevant state from the newest prompt), and adding it in to the prompt to give the agent short-term memory of its previous conversations. This feature is coming soon!
Want to learn more about retrieval-augmented generation? Checkout this explainer below.
What is retrieval augmented generation (RAG)?
Retrieval augmented generation refers to “retrieving” knowledge from a knowledge base, and using that knowledge with a text generation model by appending the information in the context window, which then is used as input to the model.
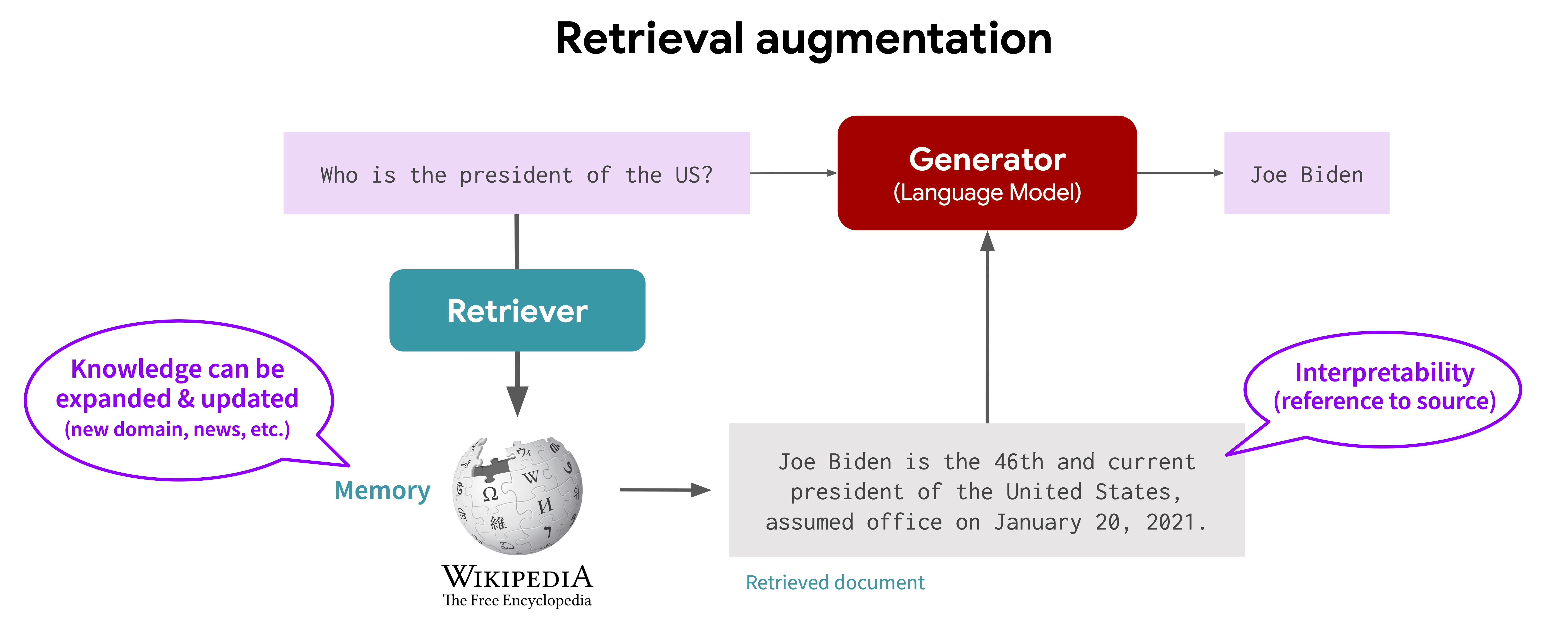 A RAG pipeline, image courtsey of RA-CM3 blog
A RAG pipeline, image courtsey of RA-CM3 blog
Some common use cases for RAG might be if you want to introduce some new knowledge to be used by the model (e.g. chat with your PDF, wikipedia, or browsing) or reduce hallucination by retrieving relevant info to give to the model.
What’s RAG good for?
- giving your model specific information to answer questions through adding short-term memory (via the Retriever)
- reducing hallucination by giving model access to real-time information that wasn’t in the original pretraining data
When will RAG not work?
- giving the model a new understanding of a new task
- conforming to style and formats (use fine-tuning instead)
- reducing context window and length used in generating new info
RAG and fine-tuning can often be used jointly: the former to add new knowledge, and the latter to conform to tone and style.
If your knowledge base is poorly curated and you ask the model to retrieve only information it has access to, RAG might backfire: the model will only be as good as the knowledge base you give it.
How to get started
- start with documents or information source to add as knowledge into the model
- turn them into a format that can be ingested by the model (e.g. through embeddings, or function calling)
- choose your retrieval method and distance of choice (e.g. cosine similarity, etc.)
- combine the content retrieved with the prompt given to the model
Resources
- Retrieval augmented generation (Langchain)
- Embedding vector databases: Supabase, Chroma, Pinecone
- ChatPDF - an example application built with RAG