


Fine-tuning
Fine-tuning the Frenrug Agent
We chose a popular open-source large language pre-trained model, and fine-tuned it on an instruction dataset. For more, here’s what we did:
Picking a base pre-trained model
We settled on a small, popular open-source pre-trained model for our use case after trying a few different open-source models. First, we made sure that prompt engineering improved the model responses as a sanity check. It did! Great. We wanted the model to conform more to the tone and use case for friend.tech, and continued onwards with fine-tuning.
Curating and creating an instruction dataset
We decided to do supervised instruction fine-tuning on the model. To do this, we looked at how the model backbone was pre-trained, and looked at a few different dataset formats needed for instruction fine-tuning on a chatting completion task. Here are some examples of different fine-tuning dataset formats.
alpaca: instruction; input(optional)
{"instruction": "...", "input": "...", "output": "..."}oasst: instruction
{"INSTRUCTION": "...", "RESPONSE": "..."}We needed to assemble 2 things: 1. instructions 2. corresponding sample completions (good examples for the model).
To create the instructions, we used a hybrid approach with 1. scraping existing online game chat histories with GPT on negotiation 2. scraping tweets and 3. manually generating human-labelled instructions. Using hand-labelled (about 100 to start with, and growing from there) instructions, we used popular close source models to synthetically generate more instructions (similar to the approach in Alpaca-LoRa).
To create the completions, we used a mix of human and synthetic generation. For rows where the instructions are from existing user negotiations and there were responses from other models, we synthetically asked GPT to convert each response into our context. For tweets and manually generated content, we hand-labelled golden responses for the model.
We had to go through various iterations of dataset curation, from a couple hundred, to more, for augmentation.
Choosing an efficient fine-tuning method
Full fine-tuning requires a lot of time and compute, particularly for large models. Given the constraints for this app, we decided to do parameter-efficient-fine-tuning, where we freeze most of the model weights and only fine-tune a very small portion (< 1%) of its weights.
We tried both low-rank adaptation (LoRA) and quantized LoRA (QLoRA).
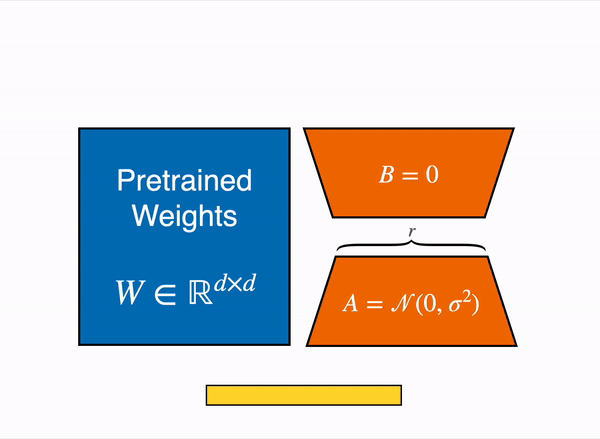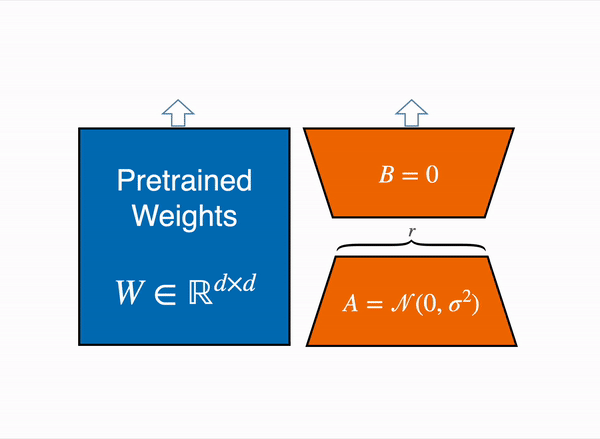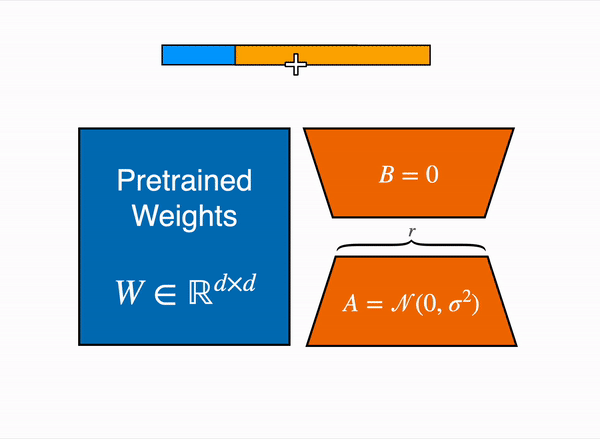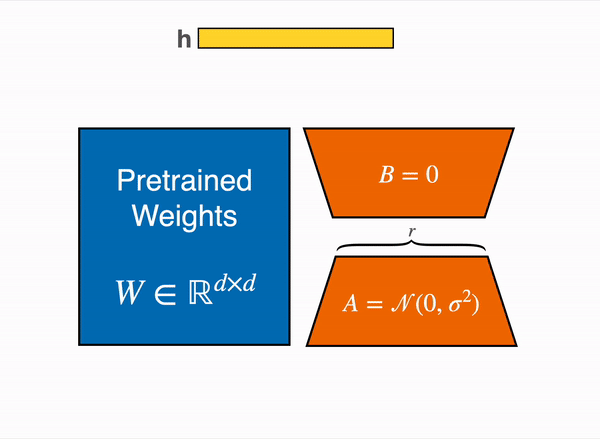 LoRA uses some clever tricks to reduce the number of trainable weights. Gif courtesy of HuggingFace.
LoRA uses some clever tricks to reduce the number of trainable weights. Gif courtesy of HuggingFace.
Fine-tuning and hyperparameter selection
There are many different choices to make during fine-tuning. For LoRA and QLora, the choices to make were
- which parts of the model to fine-tune (target modules, such as attention blocks, linear layers, and more)
- number of epochs to run for
- rank to specify in LoRA / QLoRA
We decided to use an open-source library to do the fine-tuning that supported LoRA, QLora, the model we chose, and the dataset format. Each run only took about a couple minutes to run for a small number of epochs (no more than 20). See resources for libraries you can use to run fine-tuning without too much hassle, directly from the terminal.
We used some tools to log our fine-tuning runs, namely Weights and Biases to see if the model converged as the fine-tuning experiments ran. You can use your own favourite logging tool.
Choose the best fine-tuned model
After a few iteration cycles, we tried the same prompt on fine-tuned models with a few different hyperparameters, and manually evaluated which one seemed the best for our use case. There were some iteration cycles on re-collecting data, and formatting datasets to obtain the best results.
Serve, iterate, and repeat
Serving a fine-tuned model can be as straightforward as serving a base model. We used an open-source supported inference server to serve our QLoRA fine-tuned models. It turns out LoRA and QLora fine-tuned models can be easily swapped in at serving time: all you need to do is download the fine-tuned weights (and not the original pre-trained weights), and merge with the existing pre-trained weights.
Once we obtained our fine-tuned model, we served it with a few different prompts and continued onto the summarizer step.
Want to learn more about fine-tuning? Checkout this explainer below.
What is fine-tuning?
In building a model to do what you want, there are mostly 2 main steps: general pre-training of a base model (very compute-intensive, learn general things from very large datasets, creation of models such as Llama, GPT3/4), and fine-tuning (pick a pre-trained base model, learn fewer completions to adapt to the task you need).
In general, most people will not need to pre-train their own large language model. Fine-tuning is often a technique combined with other model adaptation techniques (such as Reinforcement Learning from Human Feedback (RLHF), prompt-engineering, and more).
Fine-tuning in deep learning, more generally refers a way to do model adaptation by using the finished weights of a pre-trained model, and changing them on new data. In some ways, it can be simply understood as “continuing training” from a previous checkpoint. Developers can specify whether to fine-tune only on certain parts of the network (and freeze the parameters that don’t need to be changed to reduce cost), or all of it, depending on exactly what they need.
There are many different techniques in fine-tuning. In this brief, we specifically walk through fine-tuning for LLMs, particularly supervised instruction fine-tuning (SFT).
When and why would you use fine-tuning?
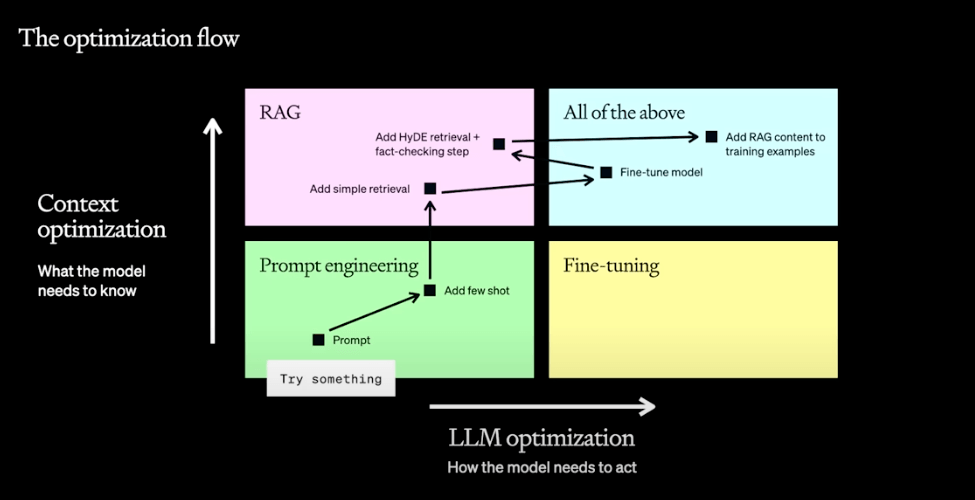 Adaptation Graphic Courtsey of OpenAI Dev Day
Adaptation Graphic Courtsey of OpenAI Dev Day
Most people try fine-tuning if
- prompt-engineering is seeing some improvement, but they want something a bit better OR
- they want to improve model performance on a specific task where their task adheres to some specific format, tone, or structure OR
- they want to reduce the number of prompt tokens and cost needed to perform well on a task.
A common fine-tuning task that works well might be teaching the model to talk like someone (from social media, texts, or more). Sometimes people use fine-tuning to also uncensor models that have undergone safety finetuning (e.g uncensored Llama).
A bad fine-tuning task might look like trying to get a text-generation model to learn some specific new information about the world (e.g. shifting knowledge cutoff, for example remembering or learning about what happened in 2023/2024). Fine-tuning isn’t very good at adding new knowledge to the base model.
If prompt-engineering doesn’t improve your model at all, fine-tuning likely isn’t going to work either. It might mean your base model isn’t the right choice.
Catastrophic forgetting: a scary name for when a model forgets some of its base knowledge learned in pre-training during fine-tuning. If you run into this, there are a few ways to mitigate it.
Use fine-tuning if:
- you want to customize a good enough base model in tone, structure, and formatting
- you may want to uncensor models or undo safety fine-tuning
- you want to teach a model more complex instructions and behaviour without using more tokens in the prompt
Fine-tuning doesn’t work if:
- you’re trying to add new knowledge to the base model. (use RAG instead!)
- you’re looking for a quick fix to models without knowing what datasets to use. It can be expensive to collect ground truth data for instruction datasets.
- (Instruction fine-tuning specific): open-ended questions. Instruction fine-tuning won’t work very well on open-ended tasks such as “Write me a story” without right answers.
- Instruction fine-tuning may not take into account the difference between language model objectives and human preferences. (Need RLHF to fix).
Supervised Instruction Fine-tuning for LLMs
Instruction fine-tuning is a type of supervised fine-tuning (SFT), that refers to fine-tuning with dataset that looks like pairs of instructions and responses. It’s “supervised” because it has pairs of instructions, and completions. For instance, Stanford Alpaca is an instruction fine-tuning dataset (52k number of rows) created from another model that generated the instruction set that was used to fine-tune Llama.
2 rows in an example instruction fine-tuning dataset:
Instruction: Please answer the following question. What is the boiling point of Nitrogen?
Answer: -320.4FInstruction: Answer the following question by reasoning step by step. The cafeteria had 23 apples. If they use 20 for lunch and bought 6 more, how many apples do they have?
Answer: The cafeteria had 23 apples originally. They used 20 to make lunch. So they had 23-20 = 3. They bought 6 more apples, so they have 3+6=9.Creating synthetic datasets: Sometimes people want to build open-source datasets using existing large language models. You can do a few things: start with some human labelled instructions, ask models to generate similar examples, and continue from there. \ \ You can also learn from the output of closed sourced model. Although beware, there have been results which show models can mimic the tone of the closed sourced model without improvement in the content.
Should you go for quality, or size of dataset? Recent empirical results show that smaller, high quality datasets can be used to outperform large, undercurated datasets.
What do you need to get started with fine-tuning?
- an instruction dataset (be careful choosing the right dataset!) for the model to learn from
- a fine-tuning method and specifications you’re happy with
- a base model you’ve experimented with
- some data or examples you want to evaluate the fine-tuned model on
Before and after (graphics from flan-y5)
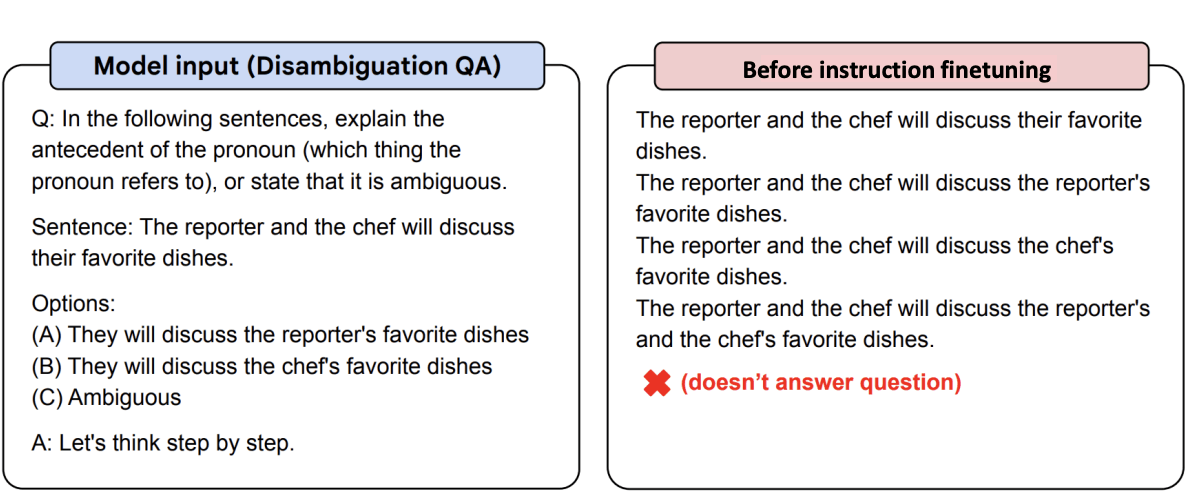 Before fine-tuning (Flan-t5)
Before fine-tuning (Flan-t5)
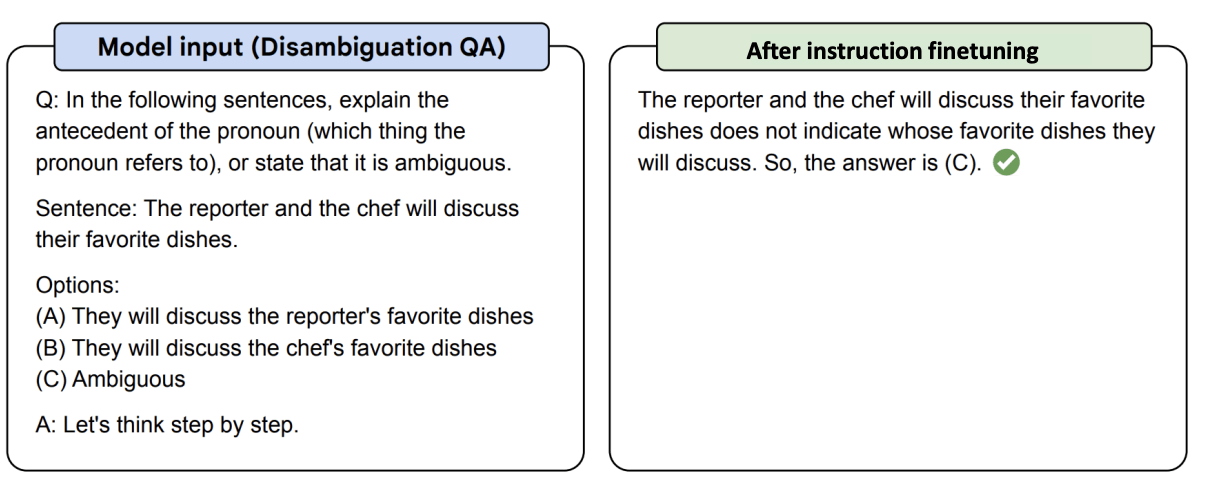 After fine-tuning.
After fine-tuning.
Voila!
Parameter Efficient Fine-tuning (PEFT)
Want to cheaply and quickly fine-tune your models? There are a few techniques to efficiently fine-tune models. Techniques such as low rank adaptation (LoRA) and quantized low-rank adaptation (QLoRA) partially fine-tunes parts of the model, and can be done within a few minutes for a few bucks, while achieving up to and about the same amount of performance as full fine-tuning. Checkout some of the below PEFT links in resources for more.